
Q1 and this first half of Q2 have been the busiest quarters at DemandSphere, to date.
We have grown faster than expected and have been working overtime to meet all of the changes that are coming to this industry on a daily basis.
We have actually released more than 10 significant new modules and feature sets since January and have even more on the way. We’re a bit behind in announcements but I wanted to do this one first because it’s a big one.
At the end of March we released into beta our new Gen AI search visibility tools. We are making this release public so that more customers can sign up and start using our platform. There are some great tools on the market and we have our own unique spin on this based on the conversations we are having with our customers.
Understanding AI search
Google is still driving the most traffic on the internet, more than any other source, for most businesses, hands down. That said, entirely new usage patterns, both in user experience (UX) and agent experience (AX), with the emergence of LLMs.
So our view is this: instead of treating Google as “traditional search” and ChatGPT, et. al. as “AI search” we believe it is more accurate to say that “all search is AI search.”
As Google made clear at Google I/O, AI is an integral part of their search offerings. And, if we’re being honest, it has been for a long time. AI search is not new, what has changed is that AI search has finally made its way to the interface between the user and the search engine.
We’ll be writing more on this topic but for now we’ll just note that we believe this to be a critical distinction.
So, at a high level, when we’re talking about monitoring visibility in AI search, we’re talking about helping brands to understand how they are seen in LLMs, particularly in the context of citations.
Most advanced users of LLMs understand the distinction between the foundational models vs. live retrieval (AKA Retrieval Augmented Generation (“RAG”)). From a monitoring perspective, simply monitoring the foundational model itself doesn’t help very much because the models are outdated almost as soon as they are released.

This means that the most interesting insights will come from when these LLMs are using live retrieval to pull in real-time search results.
Now, this where things really start to matter because the question: from where do they pull in these search results?
When we’re talking about ChatGPT, Perplexity, and other non-Google or non-Microsoft platforms, they do not yet have an internet-scale search index. Nor do they have all of the decades and billions of dollars invested in building a world-class search index.
Look at how long Bing has been at it and where are they compared to Google?
So ChatGPT, Perplexity, Claude, and others rely on the big search engines.
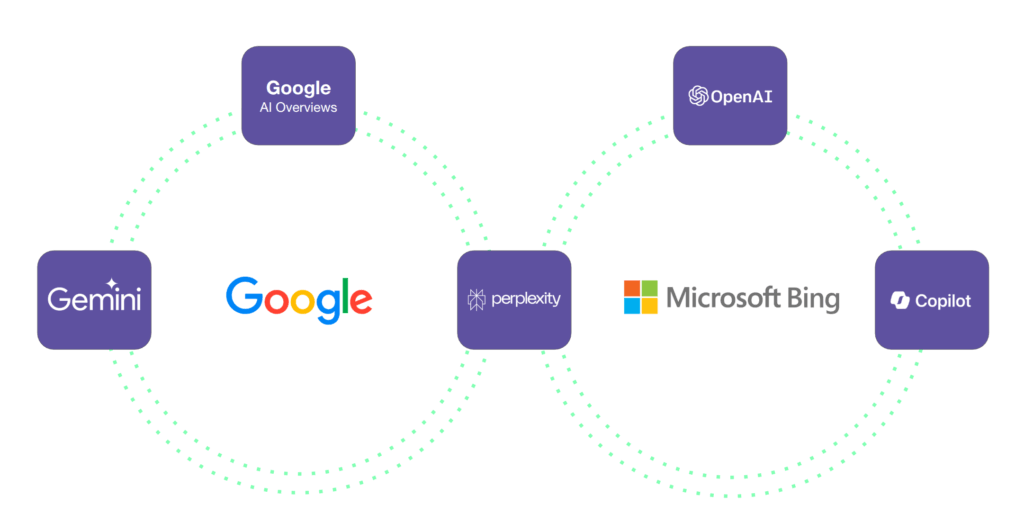
Because of the early relationship between OpenAI and Microsoft, most people assume that this search data is coming from Bing.
But that is not what our research and data reveal.
In fact, our data shows that ChatGPT is getting its results more than 50% of the time from Google. And it’s about 14% of the time from Bing.
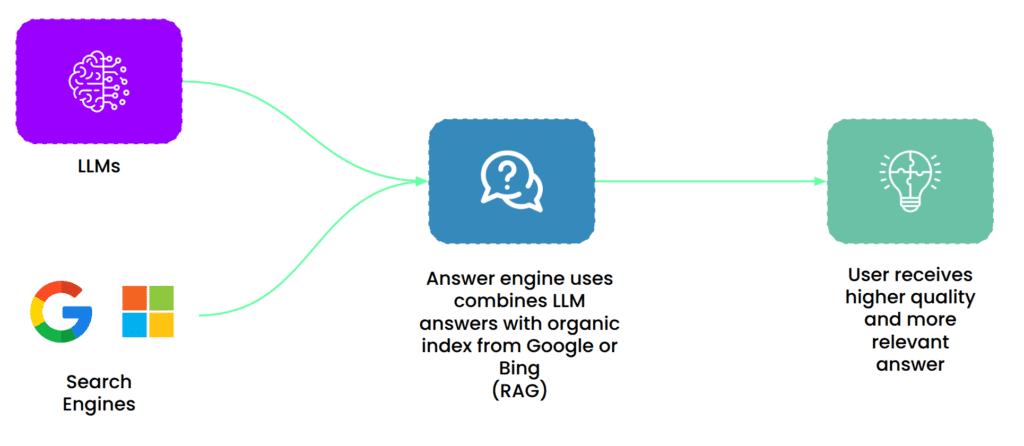
This means that the majority of Gen AI citations appear in the LLMs because they appear in either the Google or Bing search indexes.
This also means that personalization of the search index for these requests is also not happening. This is one of the many reasons that, despite personalization, there will always be value in understanding the shape and presentation of the unmediated search indexes.
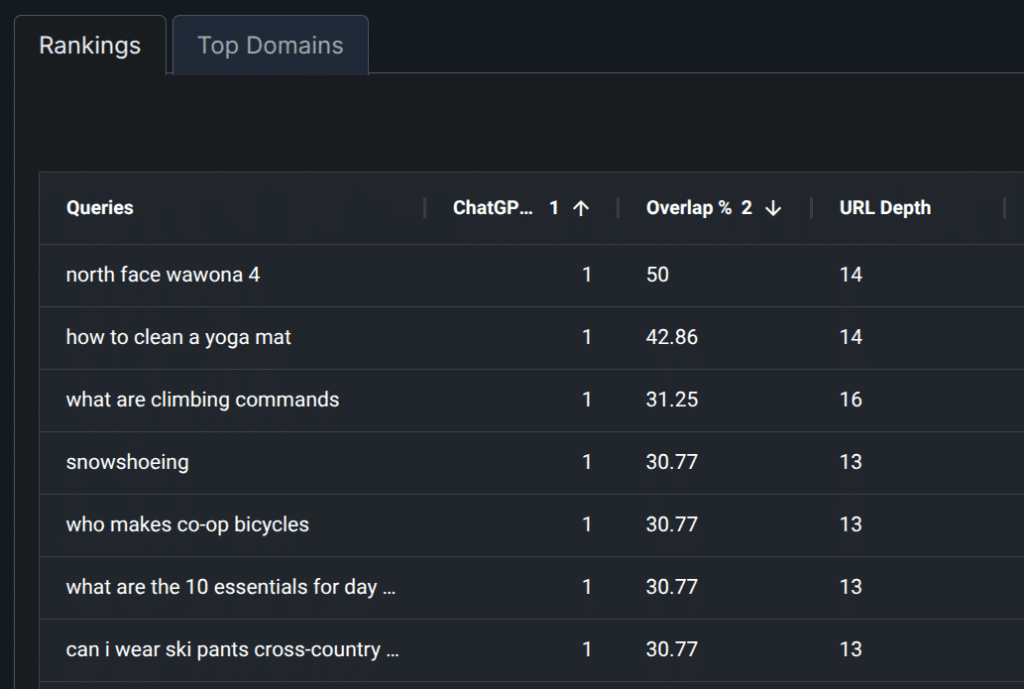
In the case of Google, both with AI Mode and AI Overviews, in one way or another, the unmediated search index (in this case, their own) will always be a factor. If that were not true, you could make the case for firing their entire search team and we all know that’s not going to happen.
How our AI search monitoring works
We simulate conversations on ChatGPT and Perplexity, along with Google and Bing, for the same queries and provide analytics into a brand’s visibility both within the model response and the citations.
We have built both a visibility tracker and Share of Voice (SoV) model to help companies understand their current positioning relative to tracked and untracked competitors.
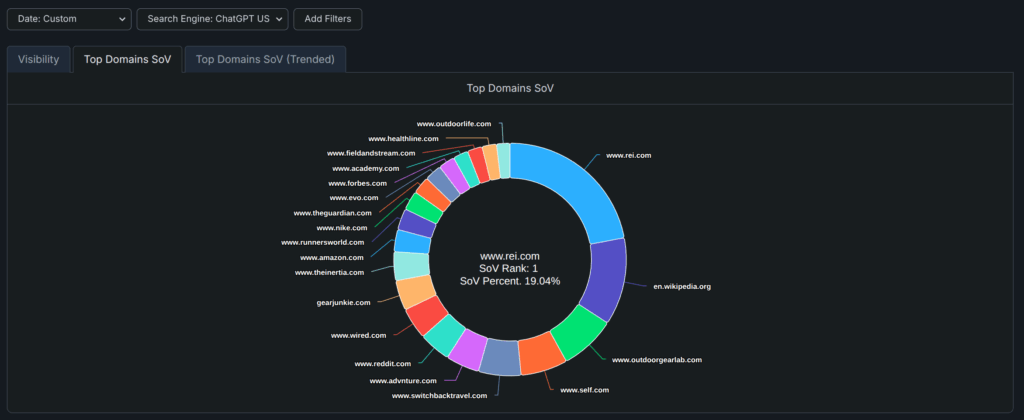
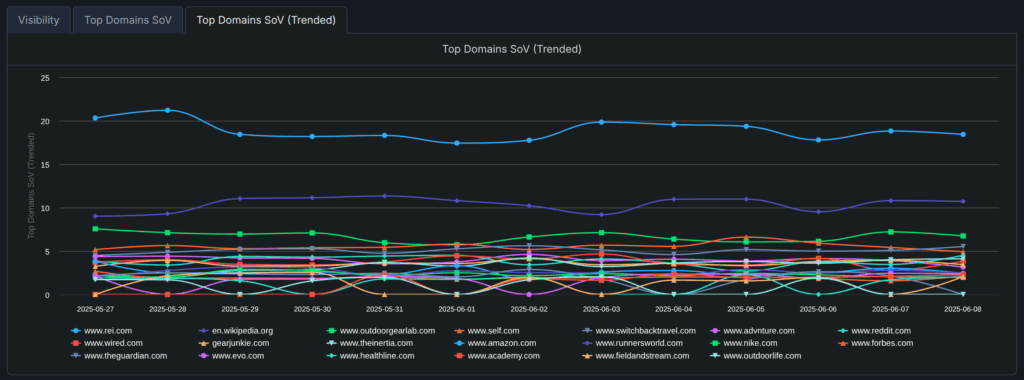
The real power in monitoring all of these sources at one time is you can analyze which search index is being used, which can vary quite a bit depending on your brand, audience, and queries. We make it easy to understand which index is the most relevant because that provides a big clue on where to focus when optimizing for these topics.
Prompt Research and Discovery
One of the challenges in monitoring AI search is in prompt discovery.
Specifically, how do you know what to monitor, especially when there is no Google Search Console, there is no Keyword Planner, there is no search volume that can be backed by anything other than “machine learning” and “modeling” (which is fine as far as it goes but it is a black box)?
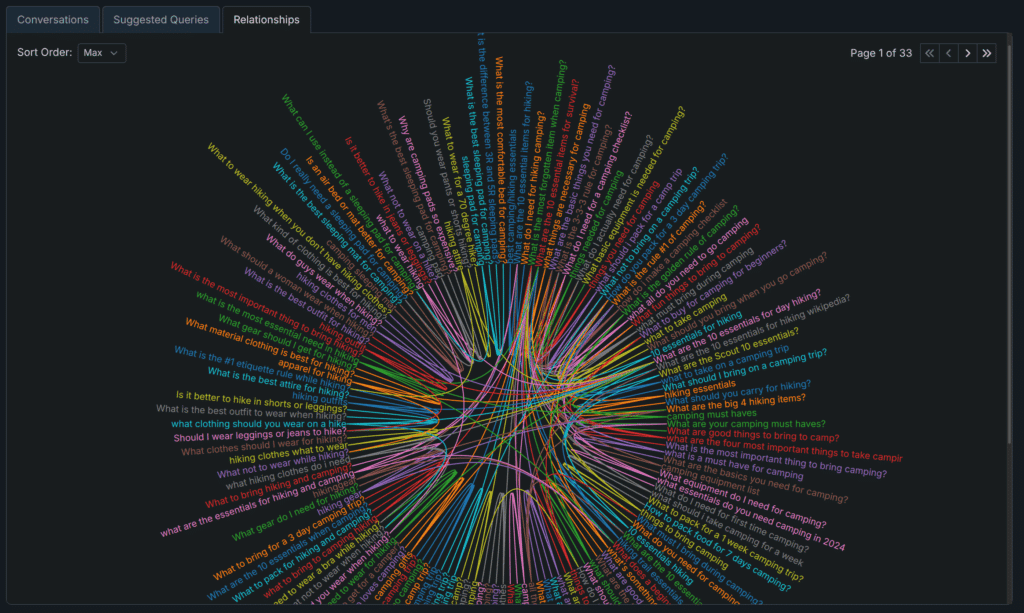
We’ve build a query mining solution that pulls in data from a variety of different sources as part of our Suggestions Explorer. This helps teams quickly get up and running with conversations and queries that are both relevant to their brand, topics they care about, and has the advantage of being backed by real data.
BigQuery and automated data pipelines
Because of the way our platform and data pipelines are set up, we were able to build this new feature set on our existing infrastructure.

This means that all of the advantages of our automated data pipelines are all there, enabling native support and import into BigQuery and other data warehouses. Our API is receiving updates as well, so you’ll have full flexibility.
The only SERP platform with native embedding-generation for content analytics
Vector embeddings (in addition to transformers) are the two most revolutionary innovations in AI technology to date, and I have a feeling that we are still just scratching the surface.
Because of this reality, we have made a commitment early on to make vector embeddings a first-class object in our platform.
This is somewhat easier said than done for an operation of our size and complexity, because there are a lot of moving pieces. But, so far, the result has been well worth it and we are just getting started.
This integration uses Google’s native embedding models and vectorizes both content that is visible in the AI Overviews as well as the AI Overview summary, and then compares the two to calculate cosine similarity.
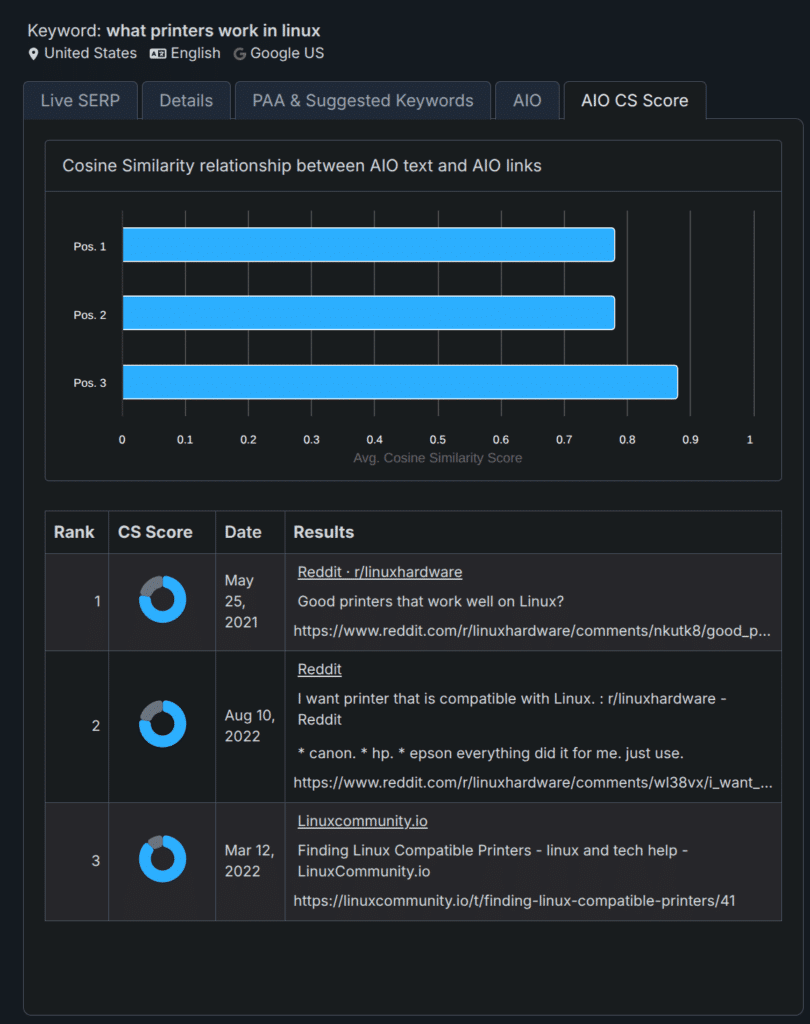
Now that we have these moving parts in place, we’re actively working on expanding their use in to every area of our platform. We already have some great new features underway for this so stay tuned for more on this topic.
Next steps
If this sounds like something you want to learn more about, sign up for a demo and we’ll arrange a walkthrough and a free trial.