The Google Search Central team provided two documentation updates today, covering their stance on optimizing for AI search and included a small clarification on spam.
The first is a new AI optimization guide, Google’s first official document on how to optimize a website for generative AI features in Search.
The second is a one-line clarification to the spam policies stating that those policies now apply to generative AI responses inside Search.
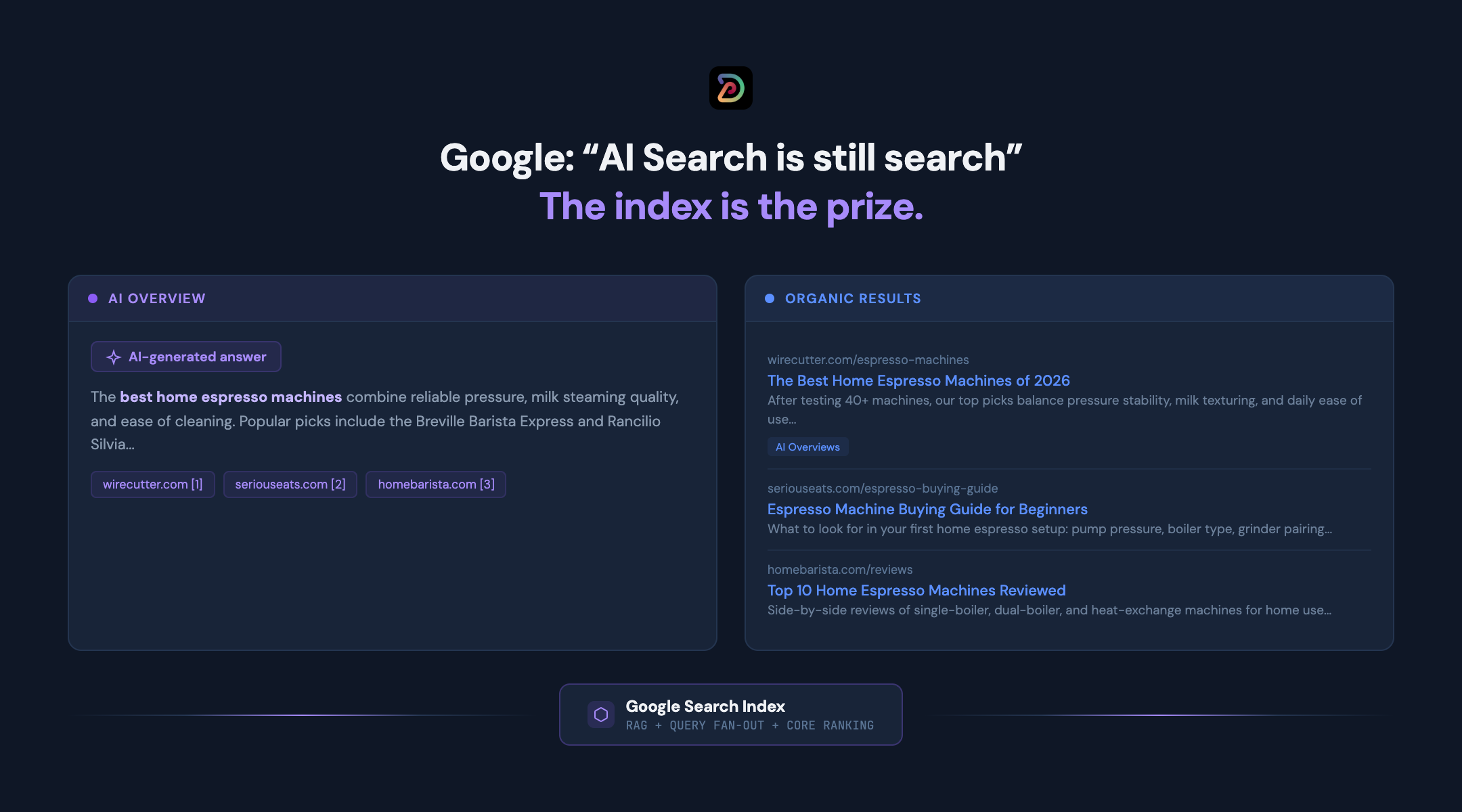
These posts represent the most direct statements that Google has made about how AI search actually works inside their stack. AI Overviews, AI Mode, and the rest of the generative surfaces are continuous with Search, not a separate product with separate rules.
This is a reality that we have emphasized for more than two years, with our slogan that “the index is the prize.”
We also take it a step further and believe it is important to understand that “all search is AI search.”
This part of the message gets overlooked a little in Google’s release here, in our view, but it is understandable given the target audience and focus of the document.
Some will view this as a strong counter-thesis to the claims of the AEO / GEO industries, and I can understand that framing.
However, this would be an overstatement in the other direction. This is why we have struck what we believe to be the correct balance with our two position statements mentioned above.
How AI features in Search actually work
The guide’s explanation of the underlying mechanism is clearer than anything Google has published before, including the May 2025 “succeeding in AI search” post that this guide effectively supersedes.
Two concepts that are central will come as no surprise to our audience:
Retrieval Augmented Generation (RAG)
Retrieval augmented generation (RAG) means the model pulls from the same Search index that powers the traditional results, then summarizes what it retrieved with clickable citation links back to the source. There is no separate AI index.
If your content is not earning placement in the index for the relevant intent, it cannot be retrieved, and it cannot be cited.
Query fan-outs
Query fan-out refers to when the model issues a set of concurrent related sub-queries derived from the original prompt to assemble a more complete answer.
Google gives the example of a query like “how to fix a lawn full of weeds” - the system may simultaneously query for “best herbicides,” “remove weeds without chemicals,” and “prevent weeds in lawn.”
These sub-queries run against the same core ranking systems, including the helpful content system that was folded into core ranking in March 2024.
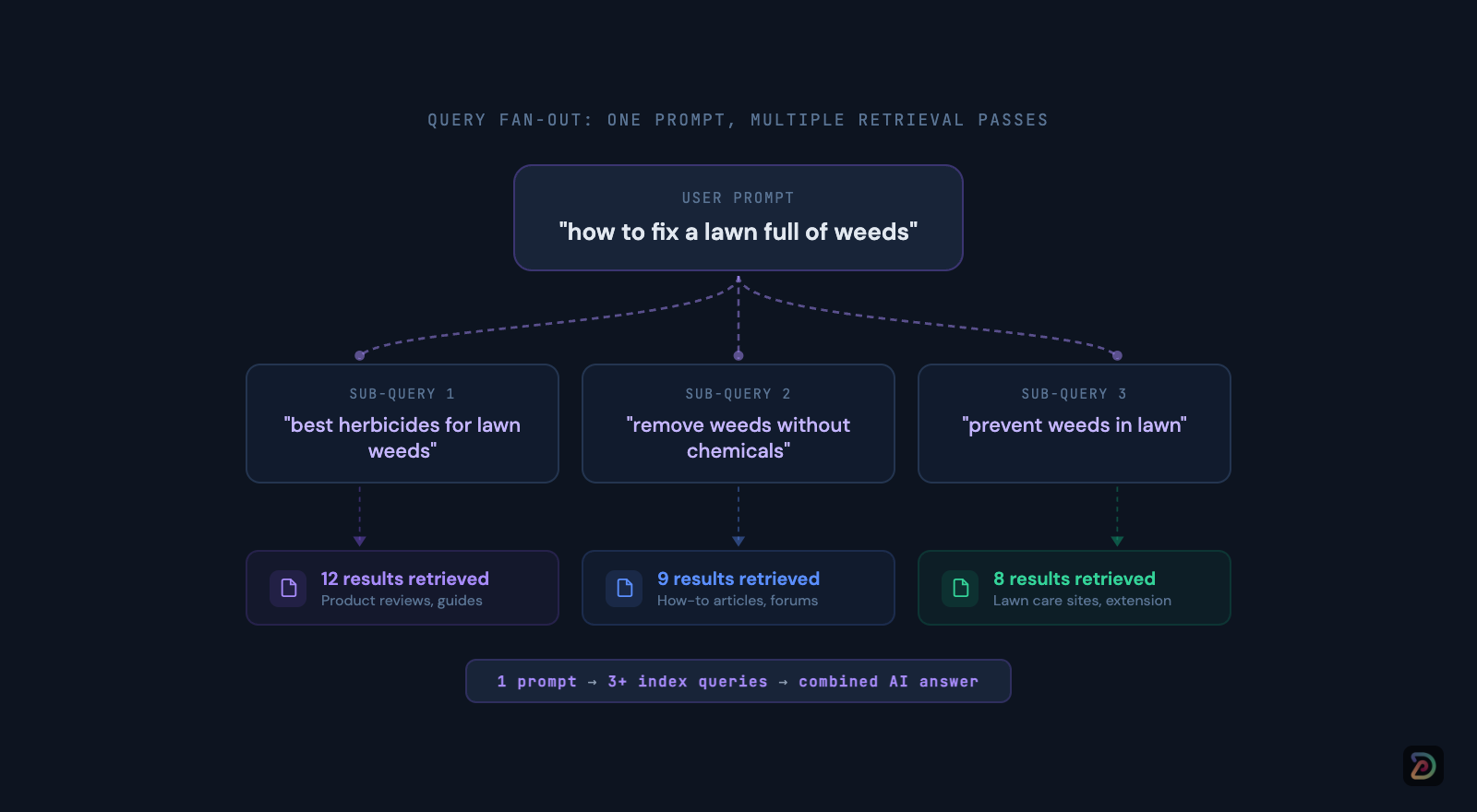
This is what we mean when we say the index is the prize.
The user-facing surface keeps changing - from Search Generative Experience (SGE) to AI Overviews to AI Mode - but the underlying retrieval layer hasn’t.
It’s the same crawl, same rendering, same ranking, same E-E-A-T signals. (A note on crawling: Google does offer a separate robots.txt token called Google-Extended that controls whether your content is used for Gemini model training and grounding. But it has no effect on Google Search, including AI Overviews and AI Mode. Those features are served by Googlebot, the same crawler that powers organic results.)
Google says it directly in the guide: “Our generative AI features on Google Search are rooted in our core Search ranking and quality systems.”
All that said, in our view, there are a few things to keep in mind.
First, the important nuance is that fan-out changes the practical shape of the content workflow.
Coverage and entity clarity matter more than they used to, because a single user query can now trigger multiple retrieval passes across related topics. The keyword-to-page mapping is mediated by the model’s interpretation of intent, and those sub-queries do not appear in any standard tool, including Search Console.
Back to the triangulation game from multiple sources, as always.
This is a key reason why we built our prompt research tools to handle synthetic subquery generation with query fan-outs in mind.
Second, there has always been a gap between what Google says and how things actually work.
The science of live retrieval continues to accelerate and the LLMs, over time, will continue to develop better indexes. Google will still be the ultimate grounding dataset for indexes for many years to come but the situation is evolving.
This is the reason it is so important to own your own data. Plan to expand your monitoring footprint, take the time to help your team get better at prompt research, and pay close attention to how the search experiences continue to evolve.
What Google says you should do
The guide is specific about what actually helps. These are the actionable recommendations, drawn directly from the document.
Create non-commodity content.
Google draws a clear line between commodity content (“7 Tips for First-Time Homebuyers”) and non-commodity content (“Why We Waived the Inspection and Saved Money”). First-hand experience, original analysis, and unique points of view are what earn retrieval. Restating information that already exists elsewhere does not.
Organize content clearly.
Paragraphs, sections, headings, and clear structure help the model identify and extract the relevant piece of a page. Google notes that their systems “are able to understand the nuance of multiple topics on a page and show the relevant piece to users.” You don’t need to chunk content into tiny fragments, just write for your audience.
Include high-quality images and video.
Standard image and video SEO best practices apply directly to AI features. There is nothing new to do here, but doing it well matters more when the model is selecting visual assets to include in an AI-generated response.
Meet the technical baseline.
Pages must be indexed and eligible to be shown in Google Search with a snippet. That means crawlable, renderable, and not blocked by robots.txt or noindex. If you’re using JavaScript frameworks, ensure that your content is accessible to Googlebot. Reduce duplicate content where possible.
Use Google Business Profiles and Merchant Center.
For local businesses and e-commerce, structured product and business data through these channels feeds directly into AI responses.
Google also introduced Business Agent, a new conversational experience that lets customers chat with your brand directly in Search.
What Google says you do not need
The guide is also specific about what doesn’t help, and this is where it most directly addresses the practices that have been marketed as “AI search optimization” over the past 18 months.
Again, keep our caveats in mind, that what Google says and does are often two different things. However, we generally agree with most of these.

You do not need an llms.txt file or special markup.
The guide states: “You don’t need to create new machine readable files, AI text files, markup, or Markdown to appear in generative AI search.” There is no special schema.org markup for AI features. Standard structured data remains useful for rich results eligibility, but it is not a factor in AI retrieval.
You do not need to rewrite content for AI systems.
Google’s models understand synonyms and general meanings. Rewriting copy to target long-tail keyword variations for AI consumption is unnecessary and, at scale, may run afoul of the scaled content abuse policy.
Our additional comment on this is that entities and knowledge graphs are the reason this is true. We still do, ironically, see many instances in our dataset of cases where direct synonyms with slight variations actually DO produce different results in AIOs and the SERPs. However, we view that primarily as an artifact of Google’s massive surface area and it is a gap that will continue to close over time.
You do not need to chase inauthentic mentions.
The guide says directly: “Seeking inauthentic ‘mentions’ across the web isn’t as helpful as it might seem.” Manufacturing brand signals through forum posts, paid placements, or astroturfing does not improve AI visibility.
There is no ideal page length.
There is no requirement to restructure pages into “AI-friendly” formats. Google says to “make pages for your audience, not just for generative AI search.”
Google also addresses the terminology question:
On AEO and GEO, the guide states: “From Google Search’s perspective, optimizing for generative AI search is optimizing for the search experience, and thus still SEO.”
This does not mean the work is identical to traditional SEO. It means that the disciplines are continuous, not discrete.
The spam policy clarification
The second update is a one-line clarification to the spam policy documentation, stating that Google Search spam policies now apply to generative AI responses in Search.
In practice, this means scaled content abuse, site reputation abuse, expired domain abuse, link spam, and the rest of the catalog from the March 2024 spam policies update are formally in scope for AI Overviews and AI Mode citations.
If a site was demoted in the traditional results for any of these violations, it is also excluded from the AI citation pool.
This is a big update.
AI Overviews citations have been one of the lower-quality surfaces (to put it mildly) in Search over the past year, with expired domains, thin affiliate sites, and scaled AI content appearing in AI answers more frequently than in the corresponding organic results.
Our AI Overviews Study documents the citation source quality distribution in detail. Google is now stating that the same enforcement guidelines apply across the AI surface.
We expect this to be enforced gradually but with increasing intensity over the coming quarters.
What this means for how you measure visibility
If the AI surface runs on the index, and the spam rules follow you across the surface, then the core of visibility work in 2026 (and beyond) covers a lot of what it has always been: be in the index, for the right entities, with the right intent coverage. There are legitimate aspects of AEO / GEO that go beyond this, but these are still the fundamentals.
The measurement layer is what continues to evolve and the reason for this is because of the rapid proliferation in AI search experiences.
Our core thesis about SERP data from way back in 2010 is that it is the most underrated source of behaviorial data on the internet.
The same thing is true for all AI search surfaces now, it’s just that there is an increasing number of surfaces to measure and monitor.
You need to track how AI surfaces are presenting your content back to users, because the same indexed page can appear very differently in an AI Overview, an AI Mode response, and the traditional results. Citation placement, source attribution, and brand mention context all vary across surfaces.
Traditional rank position alone no longer captures the full picture.
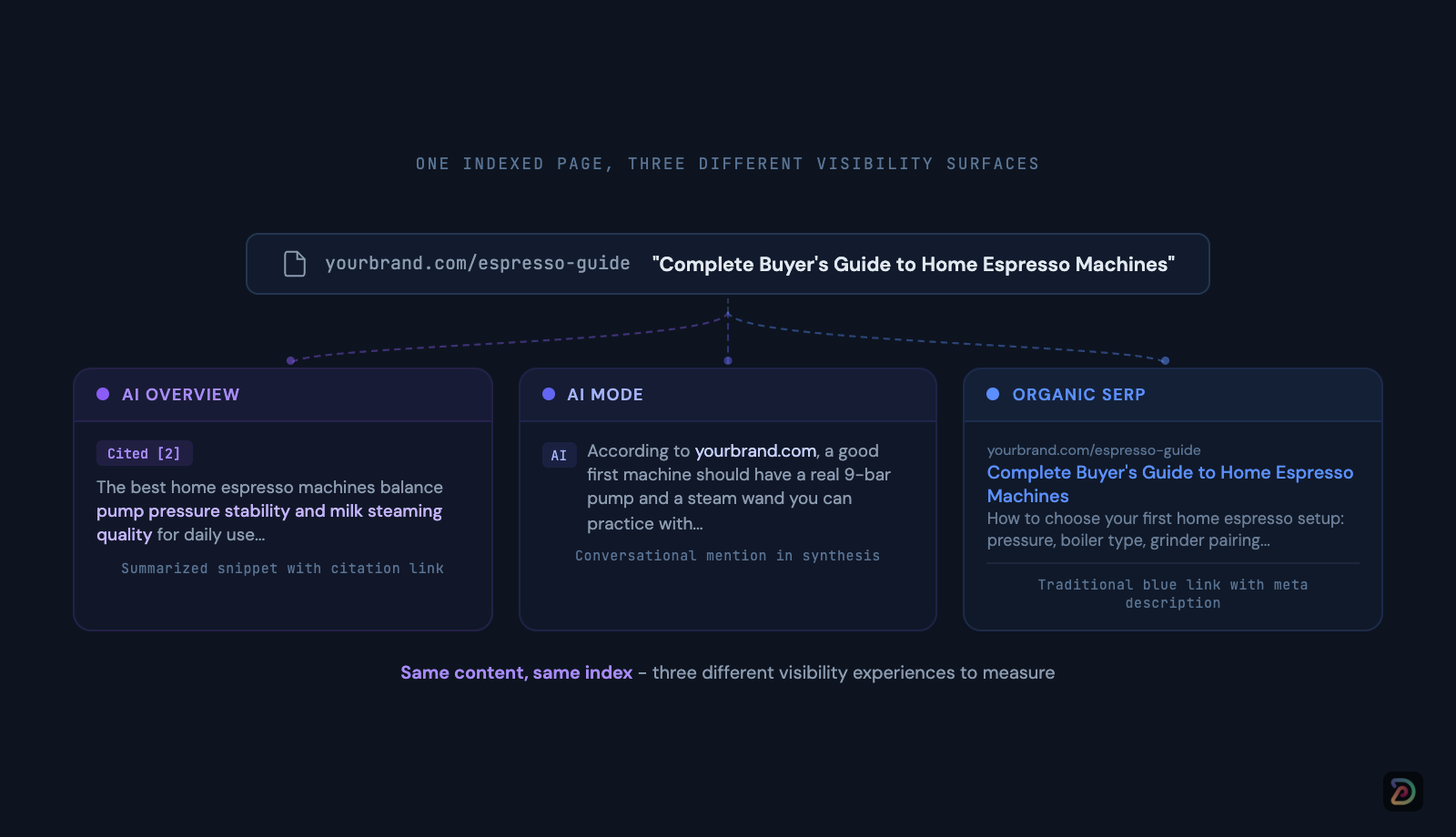
This is the split DemandSphere is built around.
DemandMetrics tracks the SERP layer at scale, including AI Overviews and AI Mode coverage.
DemandMetrics for Gen AI tracks how your brand surfaces across the broader AI search ecosystem, including Google’s AI Mode, ChatGPT, Perplexity, Gemini, and the rest of the models we follow in the AI Frontier Model Tracker.
Both data sets live on the same platform because they describe the same underlying reality: search behavior in an AI-mediated world.
Agentic experiences
The guide includes a section on agentic experiences that most readers will skim past.
Google defines AI agents as “autonomous systems that can perform tasks on behalf of people, such as booking a reservation or comparing product specifications.” They explicitly call out browser agents that inspect the DOM, parse the accessibility tree, and interpret visual screenshots to complete tasks on behalf of users.
Agent-friendly best practices
Two points are worth noting:
First Google recommends reviewing the agent-friendly website best practices for sites that want to be accessible to these systems.
Second, they reference the Universal Commerce Protocol as an emerging standard that will allow Search agents to go beyond retrieval and summary into transactional interactions. Google flagging UCP in an official document is a meaningful signal about where the agentic surface is heading.
Look beyond the browser
Apple Intelligence, Microsoft Copilot+ PC, and Google’s own efforts to embed Gemini at the operating system level all point in the same direction: the retrieval surface is expanding.
User intent may form while reading an email, reviewing a document, or using some other type of assistant, before a search tab is ever opened.
None of this is confirmed as part of Google Search today, and the guide does not address it. The overall trajectory is clear, however, that teams should be thinking about what it means for their content to be retrievable by an OS-level agent, not just a browser-based crawler.
The fundamentals discussed here (indexability, entity clarity, structured content) are the same. The surface area (AKA the user experience) will continue to expand.
We launched DemandSphere Agents for exactly this reason.
The agentic layer will require both a measurement story (how your brand shows up to agents) and a tooling story for how your team uses agents to manage search intelligence at scale.
This guide from Google acknowledges the first half, but we’re building for both.
What the guide does not cover
First, the guide is silent on the actual mechanics of fan-out query selection.
You can see the citations on an AI Overview, but you cannot see the sub-queries the model issued to assemble that answer. This is exactly the visibility gap our Prompt and Query Research tooling addresses, and it is why per-query measurement alone is no longer sufficient.
Second, the brand entity layer (what Google’s Knowledge Graph and entity systems actually know about you and how confidently they associate you with a topic) is more important than ever in an AI search world.
The guide does not address this directly. Entity-graph work, including our internal MetaIndex layer, remains a strategic focus for this reason.
Conclusion
We hope this was a useful rundown of Google’s latest guide. Feel free to hit us up with any questions, subscribe to our newsletter, and stay tuned for more.